Serverless Deployment: Resource Groups

This is Cicada Note #4 . For a background on Cicada and Cicada Notes, read Introducing Cicada.
Traditional server-side deployment uses a 1-to-1 mapping between a deployment task and a running process in production. For serverless applications this approach doesn’t scale, and so a different strategy is required. In this article I explain more about how we’ve historically defined the scope of deployment, why this doesn’t work for serverless, and a typical alternative. I also show how Cicada uses this pattern for its own deployment scoping.
The way we’ve (mostly) always done things
When we perform a deployment task with most server-side applications we update one running service. This might be a new process running in its own virtual machine, or a new service version running in container host.
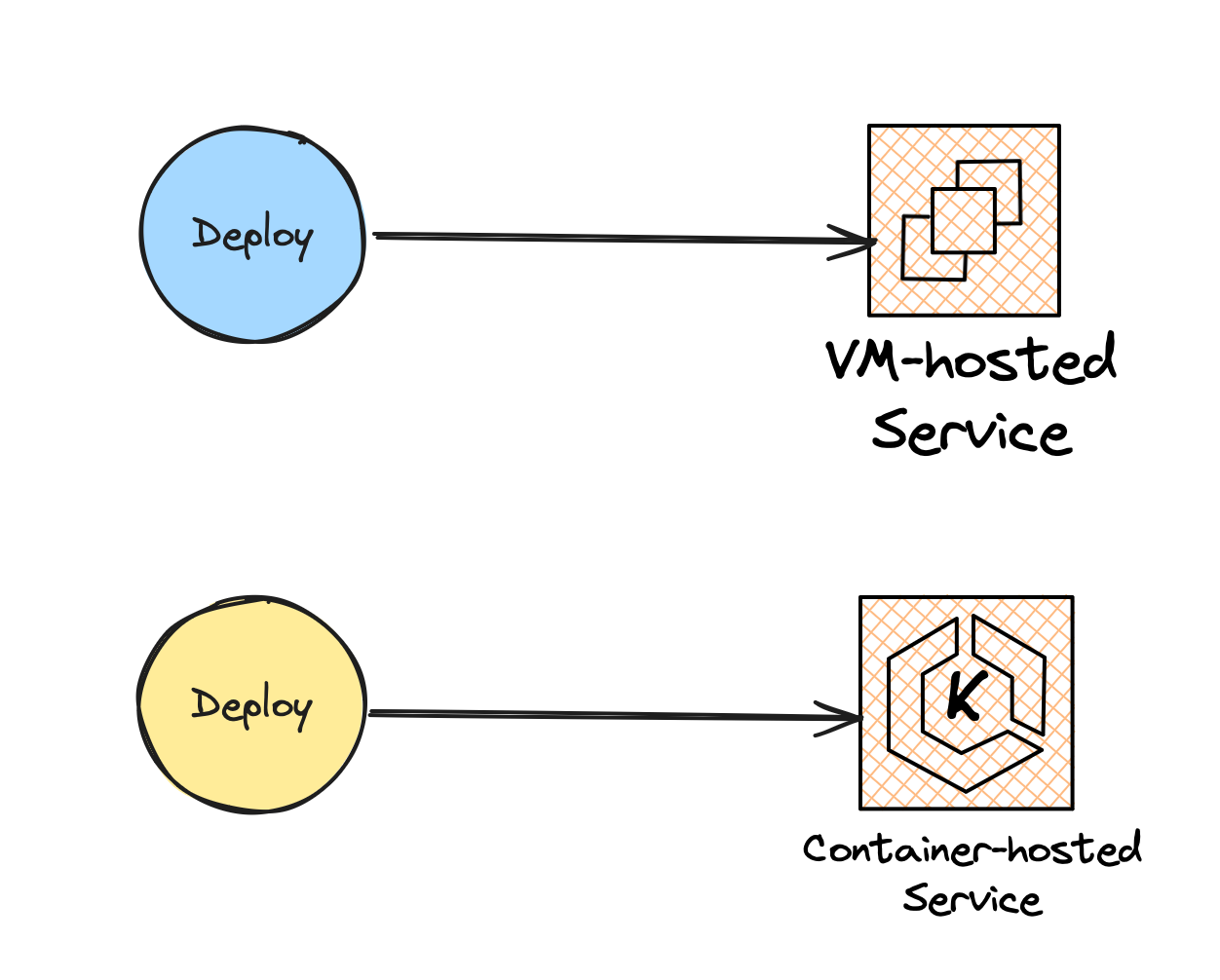
Deploy VM and Container-hosted services
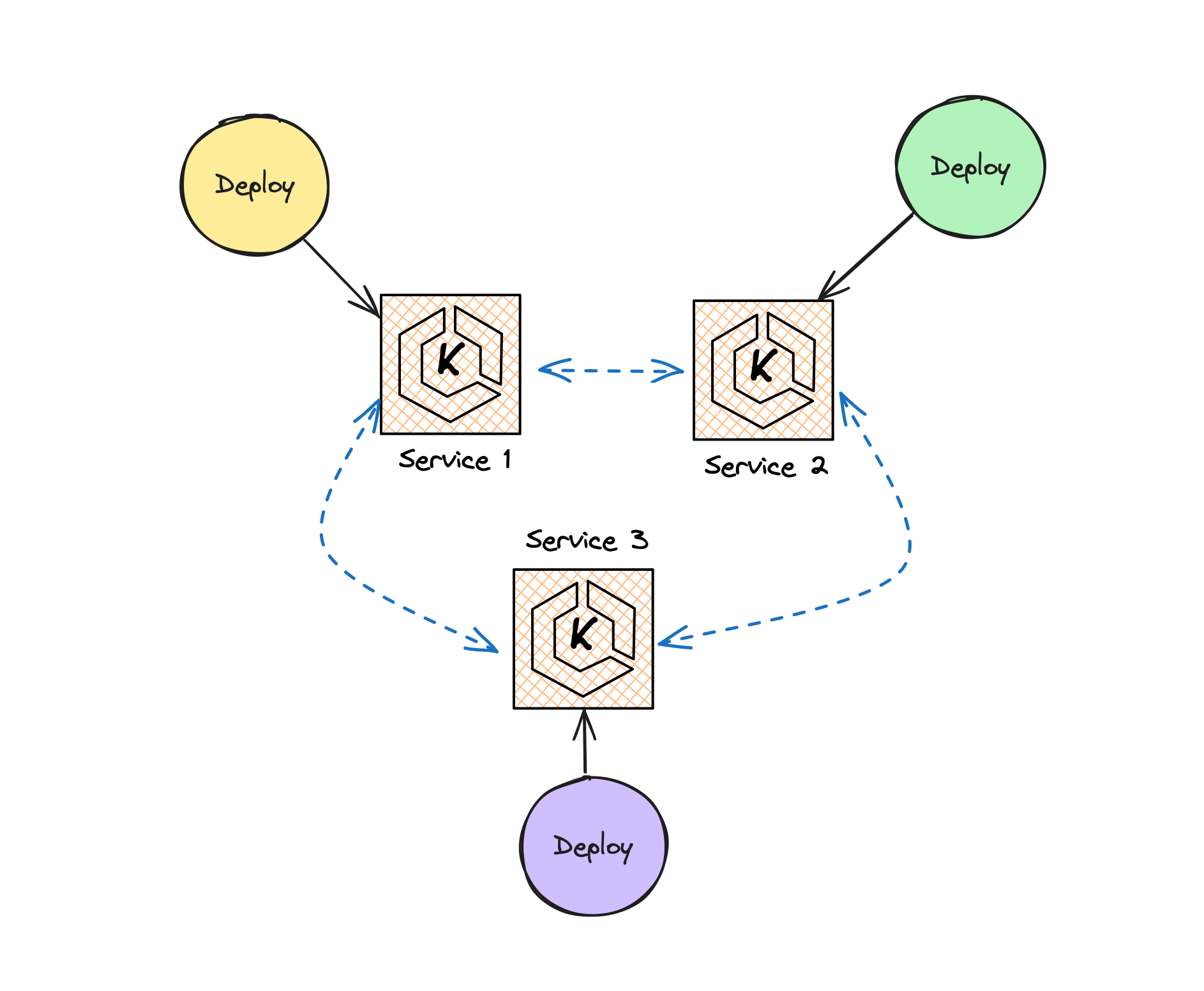
Deploy multiple microservices
For ease of explanation I’m ignoring multiple instances of one scaled service. The same concepts here apply whether there is one instance of a service, or many.
The same idea exists for PaaS platforms like Heroku or Vercel: one deployment task updates one component of a server-side application.
Serverless though requires a different approach.
Why this doesn’t work for Serverless
When we run our own code on a Serverless platform we are often using Serverless Functions or FaaS - Functions-as-a-Service. With AWS that means Lambda Functions.
One of the first things you learn about FaaS and Lambda is that you usually want to make each Lambda Function do one thing, and one thing only. There’s some disagreement in the industry about precisely what “one thing only” means (see here for my own take), but most serverless applications are going to want to use multiple FaaS Functions. Not just multiple instances of Functions, but actual different Functions with different code.
If we use the same deployment strategy for serverless applications as we do for microservices or monoliths we end up with a deployment task per FaaS Function.
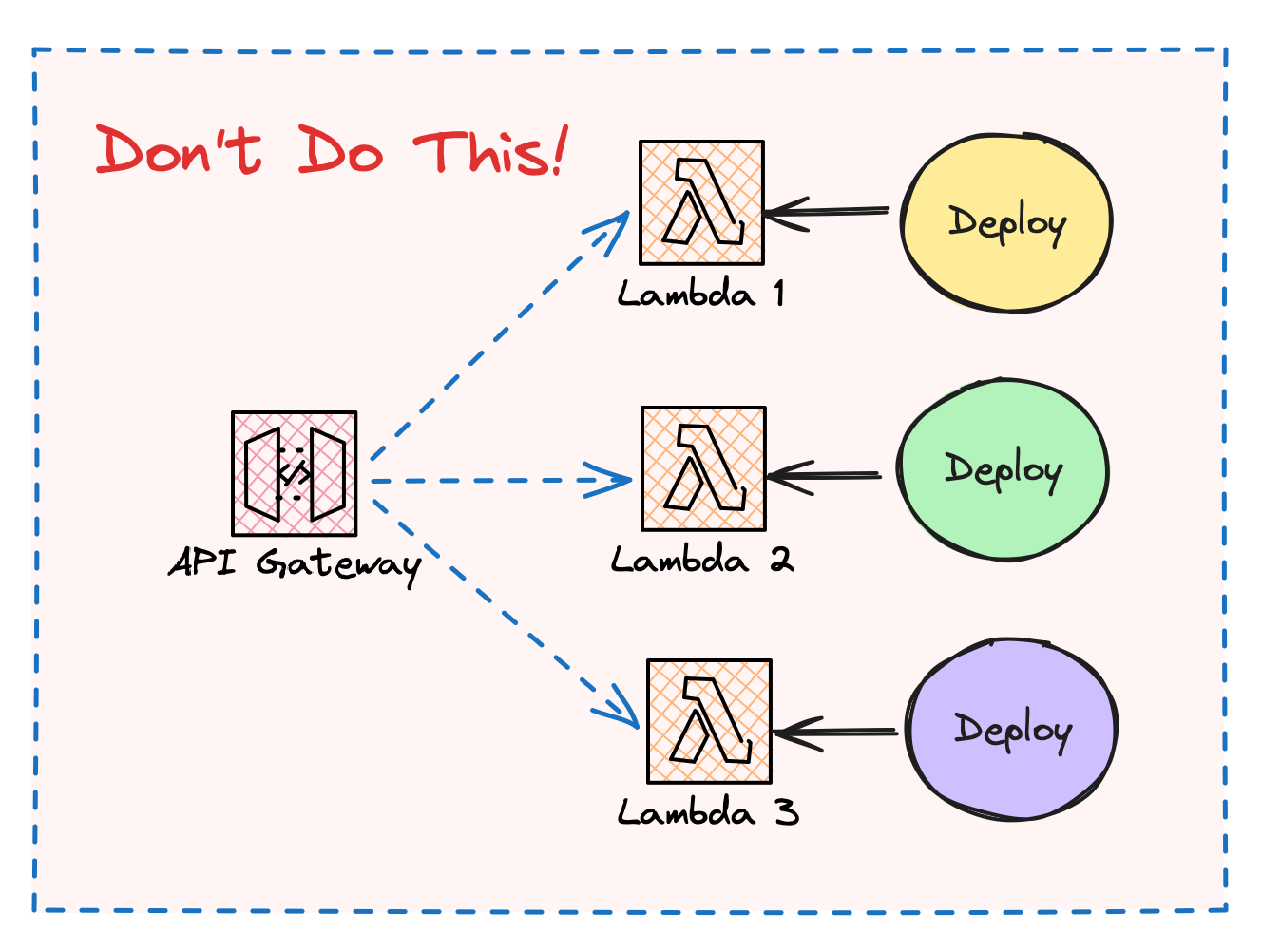
The wrong way to deploy Serverless Functions
In other words we end up with “nano services” - services much smaller than a microservice.
This is usually a terrible idea, for at least two reasons:
- Multiple-service architectures - micro or “nano” - are defined as much by their connections as they are by their service boundaries. The more services, the more connections. When we reduce the size of each service we increase the number of required services, and therefore the number of connections drastically increases. This leads to a spaghetti of inter-connectedness, or as some people have called it - “Lambda pinball”.
- If every Lambda Function requires its own deployment automation (deployment scripting and “CI/CD”) then that becomes a significant overhead.
Using a 1-to-1 mapping between a deployment task and a compute-process doesn’t scale for Serverless Functions. To avoid a cacophony of function chaos we therefore have to change a few decades of habit, and use a new model of deployment sizing.
Deploy Resource Groups instead
Instead of deploying one Lambda Function per deployment activity we deploy one group of Functions. By considering the group, rather than the individual process, as the “unit of compute” we can then settle back to our tried and trusted deployment patterns.
Serverless Functions don’t typically live by themselves - most often they are twinned with other serverless resources, like an API Gateway. And so usually what we deploy per-task in a serverless world is actually a Resource Group of Functions AND platform-service configurations.
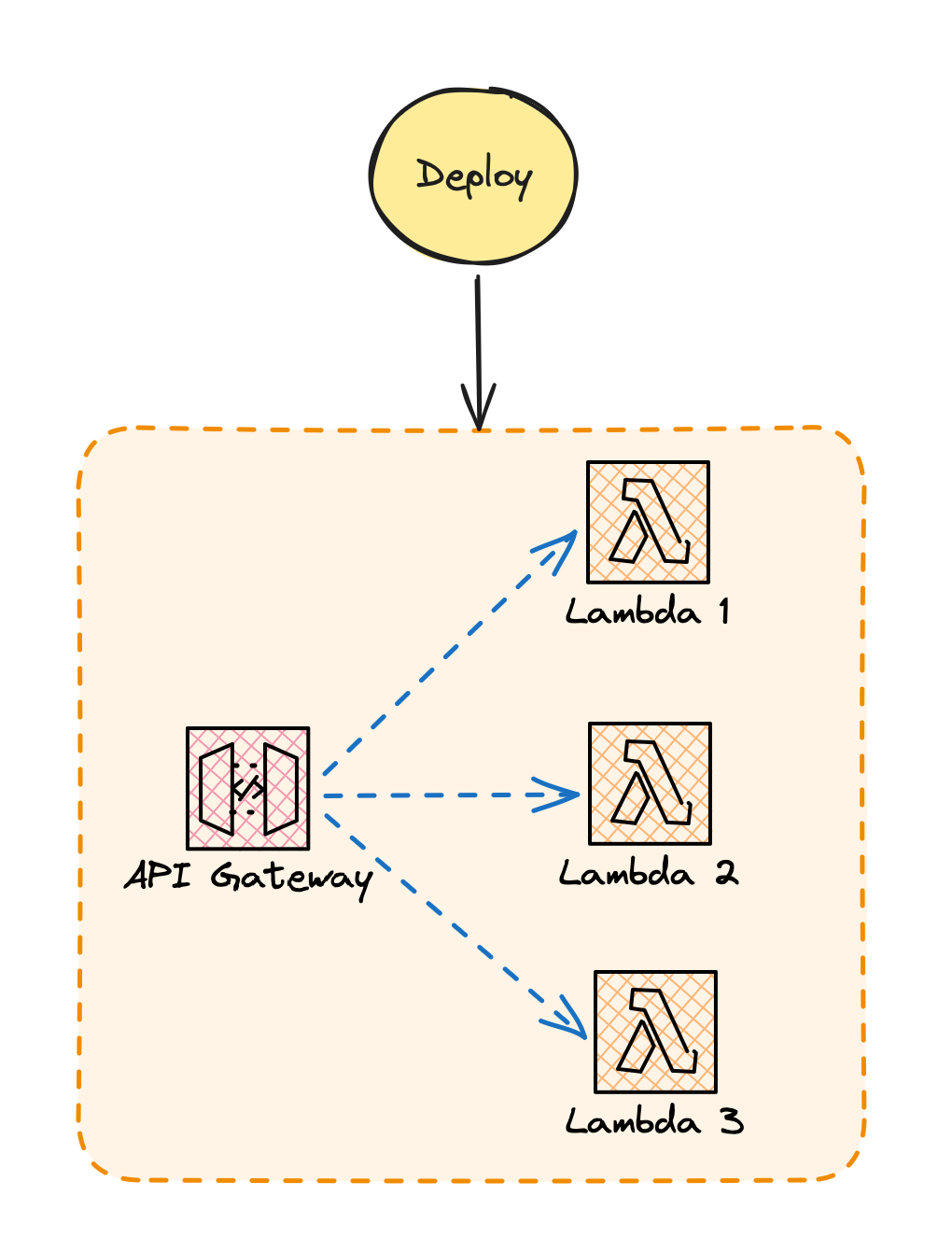
Deploying Serverless Resource Groups
The group of Functions and related resources, rather than any individual Function, defines the capability of the deployed service. The boundary, or Published Interface of the service, can be defined by something other than just the set of all the Functions in the Group - it might be the API Gateway deployed as part of the serverless service. This largely solves the “Lambda pinball” problem, but there are nuances I’ll try to write about another time.
Resource Grouping is usually structured through Infrastructure-as-Code (IaC) scripting.
Cicada as Example
Cicada is a reasonably large serverless application, consisting of several Lambda Functions, an API Gateway, message bus configuration, DynamoDB tables, and more. But the complete set of resources are deployed as one CDK Application. In other words when I run the project’s deploy action, either locally or from a GitHub Actions Workflow, then all of the Lambda Functions, plus other resources, are deployed in one activity as one group.
Cicada implements this by using CDK, which itself uses CloudFormation under the covers. Even though Cicada has a large number of resources - more than 100 total AWS elements - because I use an Infrastructure-as-Code tool I can continue to treat it as one service from a deployment strategy point of view.
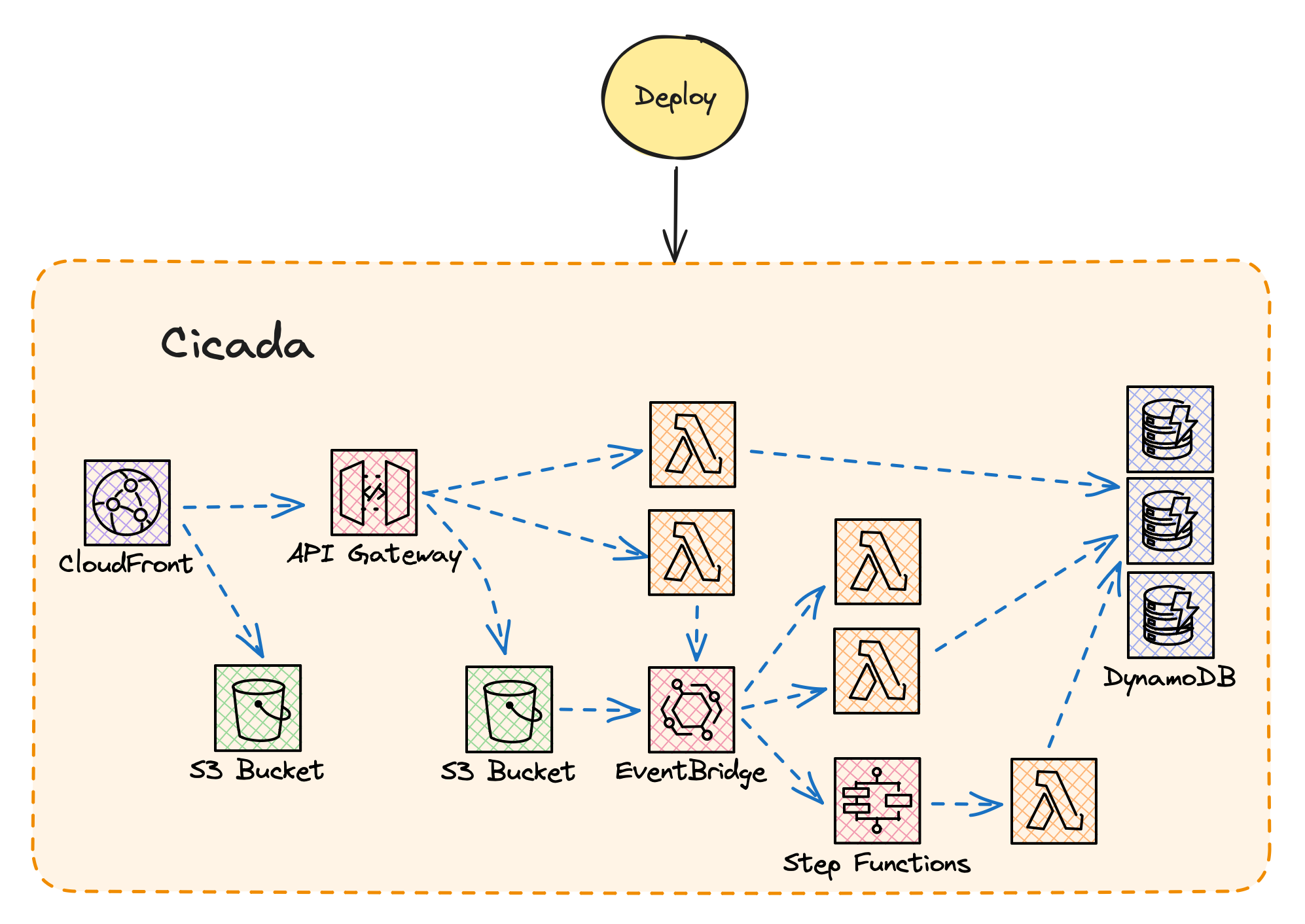
Cicada deployment
Summing up
In this article I explained why the ‘compute process as unit of deployment’ model doesn’t scale for serverless, and how instead we use a Resource Group as the target of a deployment task.
Feedback
I value hearing what people think about how I’ve built Cicada, and also my writing in Cicada Notes. If there ends up being enough interest I’ll start some kind of discussion forum, but for now please either email me at mike@symphonia.io, or if you’re on Mastodon then please kick off a discussion there - my user is @mikebroberts@hachyderm.io .